When Code Smells Twice as Much: Metric-Based Detection of Variability-Aware Code Smells-- Supplementary Material for SCAM 2015 -- |
When Code Smells Twice as Much: Metric-Based Detection of Variability-Aware Code Smells-- Supplementary Material for SCAM 2015 -- |
Highly-configurable software systems (also known as software product lines) gain momentum in both, academia and industry. For instance, the Linux kernel comes with over 12,000 configuration options and thus, can be customized to run on a variety of system with different properties such as architecture or processor. To a large degree, this configurability is achieved through variable code structures, for instance, using conditional compilation with the C preprocessor. Such source code variability adds a new dimension of complexity and thus, giving rise to new possibilities for design flaws. Code smells are an established concept to describe design flaws or decay in source code. However, existing smells, so far, had no notion of variability and thus fail to suitably characterize flaws of variable code structures. In previous work, we addressed this lack of varibaility support by proposing an initial catalog of six variability-aware code smells [VaMoS 2015]. In the respective paper, we discuss the appearance and negative effects of these smells and present code examples from real-world systems. To evaluate our catalog, we also conducted a survey amongst 15 researchers from the field of software product lines. As a key result of this survey, we can confirm that our proposed smells a) have been observed in existing product lines and b) are considered to be problematic for important software development activities, such as program comprehension, maintenance, and evolution. However, so far we have no empirical evidence how common these smells are in software systems. In our paper (belonging to this page), we propose a metric-based method to detect variability-aware code smells. In particular, we evaluate our method with one smell, Annotation Bundle in five real-world software systems of medium size, namely: emacs, vim, php, lynx, libxml2. On this page, we provide supplementary material for both, our detection methods as well as the empirical study.
For detecting our proposed, variability-aware code smells, we built a tool called Skunk, in with we implemented our metric-based detection algorithm. Our vision is to extend Skunk in an iterative manner, thus, adding more and more variability-related smells, but also improving the detection algorithm itself. While currently only focussing solely on variability-aware smells, it is generallly possible to extend Skunk for detecting traditional smells. Below we provide an overview of the overall workflow of Skunk.
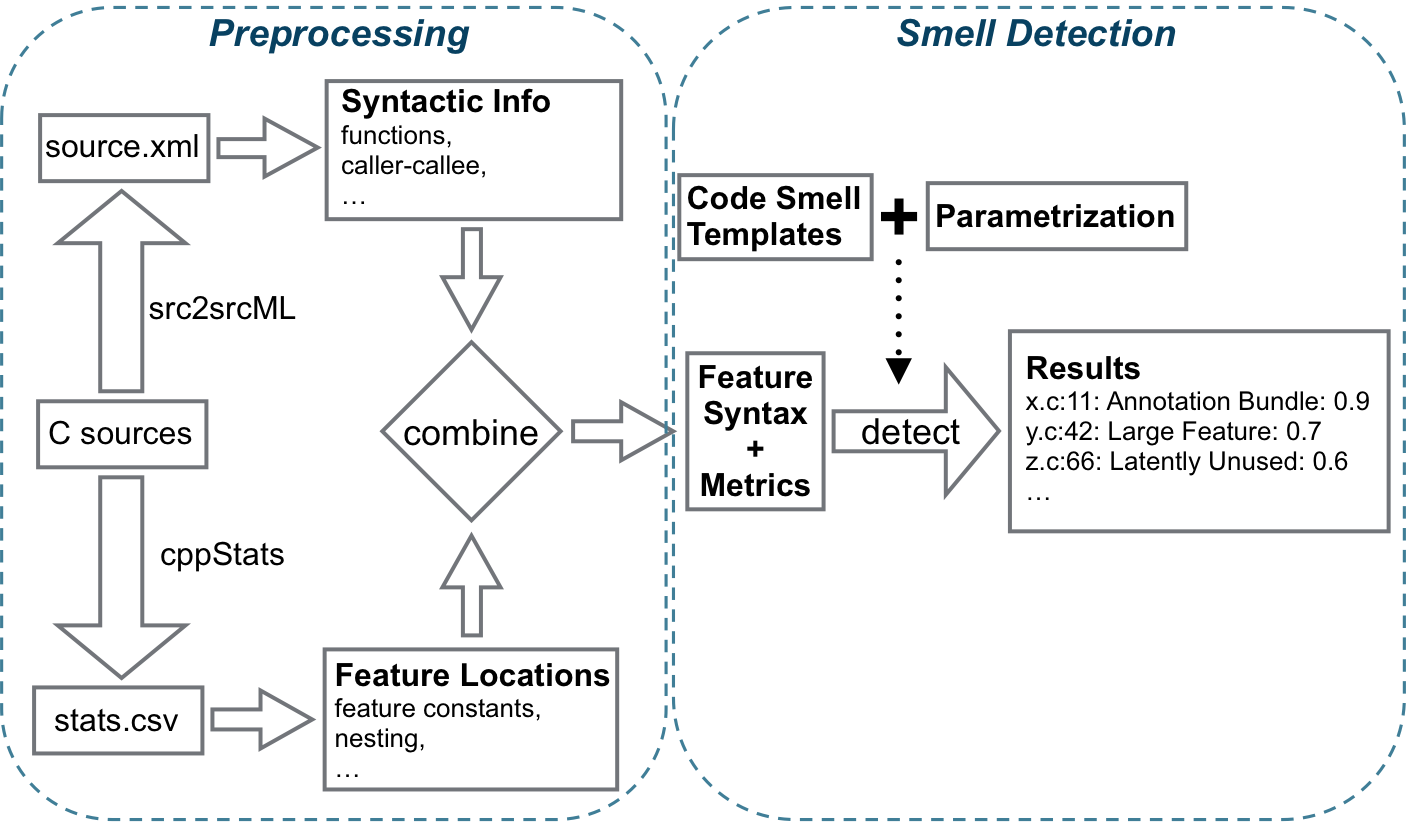
In the first step, we analyze the subject system in order to
extract metrics, used for the second stept. To this end, we
employ two existing tools: CppStats (website) and src2srcML (website).
While CppStats extracts a
variety of metrics, covering the nature of CPP variability in C
programs, src2srcML basically
provides an AST-like representation of the program in XML
format. From the latter, we extract additional information, such
as locations of function definitions or function calls.
Since src2srcML is integrated
in CppStats, it is
sufficient to run CppStats only to obtain
the XML-like source code representation, provided src2srcML.
For more information about CppStats, including the
source code, we refer to the corresponding github repository: https://github.com/clhunsen/cppstats
Based on the extracted data, we perform the actual code smell detection in the second step. To this end, smell-specific metrics are used and a corresponding code smell template is provided to parametrize thresholds for particular metrics and change weighting factors. Details for paramtrization of the Annotation Bundle smell can be found in the paper. Then, the smell deteciton algorithm uses these templates during detection to filter out those code fragments (e.g., functions) that are below specified thresholds (in case that those are marked as mandatory). Finally, a list of potential smells is obtained and stored as .csv file. Skunk is available on Github https://github.com/Dwelgaz/Skunk, containing the sources and a HowTo.txt file that describes how to use it. Give it a try!!
For the evaluation of our metric-based method, we conducted a case study, comprising five open-source software systems: emacs, libxml2, lynx, php, and vim. Next, we provide both, the results for the initial result set (after clone detection) and for the reduced sample set. For the latter, we also provide the respective C functions extracted in separate files, together with information about its original location.
For our detection method, we propose several metrics, used to finally spot potential Annotation Bundle smells. While they are basically subsumed by the overall metric, AB-smell, proposed in the paper, we list all of them in the initial result set (see above). Hence, we briefly explain the particular metrics
| Metric | Full name | Description |
| LOC | Lines of Code | Source lines of code of the function, ignoring blank lines and comments. |
| LOAC | Lines of annotated code | Source lines of code in all feature locations within the function. Lines that occur in a nested feature location are counted only once. Again, blank lines and comments are ignored. |
| LOFC | Lines of feature code | In contrast to the LOAC metric, this metric counts annotated code multiple times if the corresponding feature expression consists of more than one feature constant. For instance, if we have 10 lines of annotated code and the feature expression is A || B, this metric would report 20 lines (i.e., the actual number of lines multiplied with number of feature |
| NOFL | Number of feature locations | Number of blocks annotated with an #ifdef. An #ifdef containing a complex expression, such as #if defined(A) && defined(B), counts as a single feature location. An #ifdef with an #else or #elif branch counts as two feature locations |
| NOFCDup | Number of feature constants (with duplicates) | number of feature constants, accumulated over all feature locations within the scope (e.g., for the Annotation Bundle smell, our scope is a particular function). Feature constants that occur in multiple feature locations are counted multiple times. |
| NOFCNonDup | Number of feature constants (without duplicates) | Same as above, but without duplicates, that is, each feature constant is counted only one time, independent of how often it may occur in the considered scope. |
| NDacc | Accumulated nesting depth | Nesting depth of annotations, accumulated over all feature locations within the scope. An #ifdef that is not enclosed by another #ifdef is called a top-level #ifdef and has a nesting depth of zero; an #ifdef within a top-level #ifdef has a nesting depth of one, and so on. Nesting values are accumulated, which means that a function containing two feature locations with a nesting depth of one is assigned an NDacc value of 2. |
Download Vim example (with cppstats/src2srcML data)
After download, extract the content to a place of your choice. In particular, the archive comprises i) the original source files, ii) the xml files, created by src2srcML (subfolders _cppstats and _cppstats_featurelocations), and iii) three .csv files, containing basic metrics, computed by CppStats.Next, you can run our smell detector on the example. To this end, you have the following options (with SKUNK_HOME being the root folder of Skunk).
--source /path/to/vim --saveintermediate --config SKUNK_HOME/CodeSmells/AnnotatioBundle_min.csmThe first argument indicates that running Skunk includes the preprocessing step. The second argument specifies that the result of the preprocessing should be stored. As a result, three .xml files will be stored in the SKUNK_HOME folder. The final argument is optional and refers to the template for the Annotation Bundle Smell, applied during code smell detection. In particular, the provided template fiel contains four mandatory thresholds, as explained in the paper.
Preprint of the paper (accepted for publication at SCAM 2015): scam2015varsmells-preprint.pdf


