

Highly-configurable software systems (also known as software product lines) gain momentum in both, academia and industry. For instance, the Linux kernel comes with over 12,000 configuration options and thus, can be customized to run on a variety of system with different properties such as architecture or processor. To a large degree, this configurability is achieved through variable code structures, for instance, using conditional compilation with the C preprocessor. Such source code variability adds a new dimension of complexity and thus, giving rise to new possibilities for design flaws. Code smells are an established concept to describe design flaws or decay in source code. However, existing smells have no notion of variability and thus fail to suitably characterize flaws of variable code structures. We address this lack of varibaility support by proposing an initial catalog of six variability-aware code smells. In our paper, we discuss the appearance and negative effects of these smells and present code examples from real-world systems. To evaluate our catalog, we have conducted a survey amongst 15 researchers from the field of software product lines. As a key result of this survey, we can confirm that our proposed smells a) have been observed in existing product lines and b) are considered to be problematic for important software development activities, such as program comprehension, maintenance, and evolution. On this page, we provide supplementary material for this survey.
To evaluate our proposed, variability-aware code smells, we conducted a survey with researchers in the field of software product lines (SPL), which is our target domain. Our goal was to have a first evaluation of our smells, based on experiences with SPL programming. Particularly, we had two questions in mind we want to answer, based on this survey: First, whether participants of the survey oberserved one or more of these smells in the described (or similar) form. Second, how participants, based on their experience, would estimate the (assumably negative) effects of these smells on program comprehension, maintainability, and evolvability.
To this end, we provided the following material for participants of the survey:
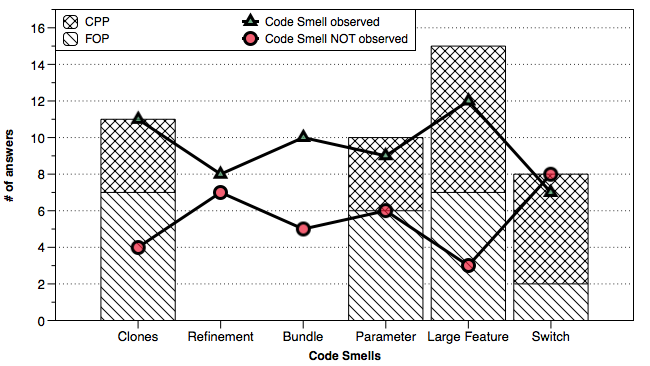 Above, we show how many participants observed our proposed code smells. Moreover, we show to what extent these smells have been observed in systems with composition-based (here: FOP) and annotation-based (here: C preprocessor CPP) systems, respectively.
Above, we show how many participants observed our proposed code smells. Moreover, we show to what extent these smells have been observed in systems with composition-based (here: FOP) and annotation-based (here: C preprocessor CPP) systems, respectively.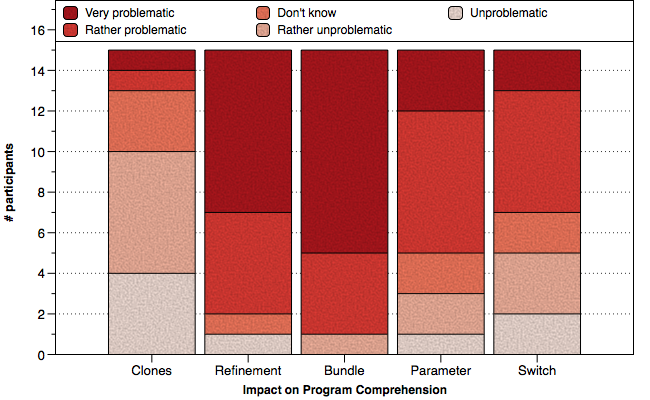 How do participants estimate the impact of our code smells on program comprehension? The bar chart above aggregates their answers and indicates that the majority assumes that the smells are rather problematic, especially Long Refinement Chain and Annotation Bundle.
How do participants estimate the impact of our code smells on program comprehension? The bar chart above aggregates their answers and indicates that the majority assumes that the smells are rather problematic, especially Long Refinement Chain and Annotation Bundle.
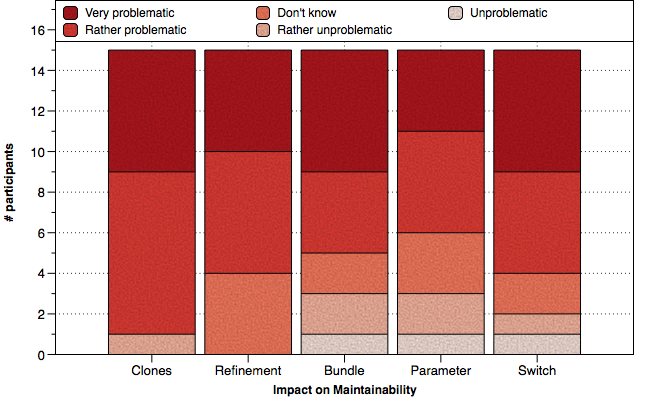 Results for the estimated impact of our smells on maintainability.
Results for the estimated impact of our smells on maintainability.
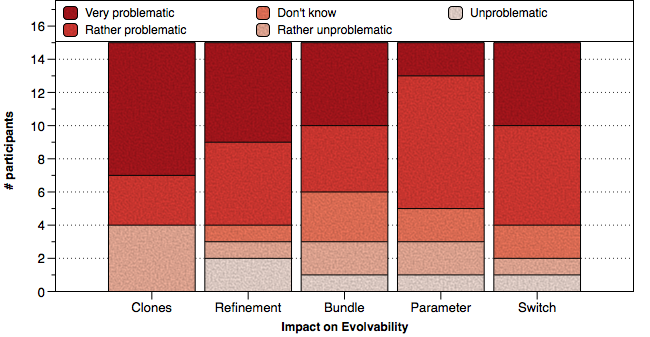 Results for the estimated impact of our smells on evolvability.
Results for the estimated impact of our smells on evolvability.
